The Octus AI Framework
AI at Octus – policies, guidelines and practices
Our AI-integrated and customer-centric architecture revolutionizes credit market intelligence and accelerates informed decision-making. Responsibly embedded. Efficiently delivered.

AI Innovation at Octus
Discover how Octus has grown its AI offerings and how that is helping credit professionals.
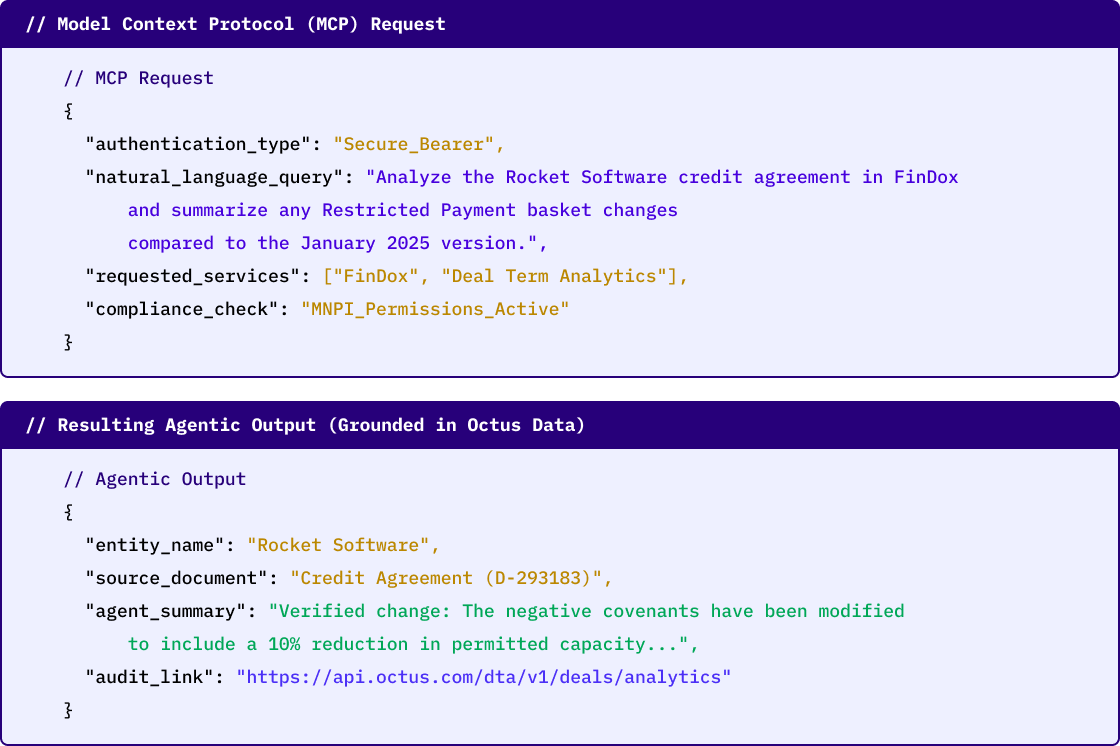
The Octus MCP connector
Your AI stack is only as good as the data powering it. The Octus MCP connector, powered by CreditAI, puts verified credit intelligence directly inside your AI environment, making Octus data natively available to your analysts and autonomous agents.
- Connect to the full Octus credit universe using natural language queries.
- Surface expert intel, covenant data, private deal documents, financial filings and private company analysis without leaving your workflow.
- Trace every output back to its original source.
The connector supports the AI tools your teams already use, including Claude and ChatGPT, and is built for both professional users and autonomous agent pipelines.
Credit data your AI can trust. Delivered where the work happens.
The power of GenAI and Octus intelligence
CreditAI by Octus®
Unravel complex scenarios and tap into real-time updates to navigate the credit landscape with precision and ease.
“Discover CreditAI by Octus®CreditAI by Octus® boasts a user-friendly interface and enables seamless interactive natural language search. We have harnessed state-of-the-art technologies, including industry-leading vector and memory databases in conjunction with LLMs fortified with our proprietary architecture and guardrails. – Sree Mallikarjun Chief Scientist, Head of AI Innovation Octus
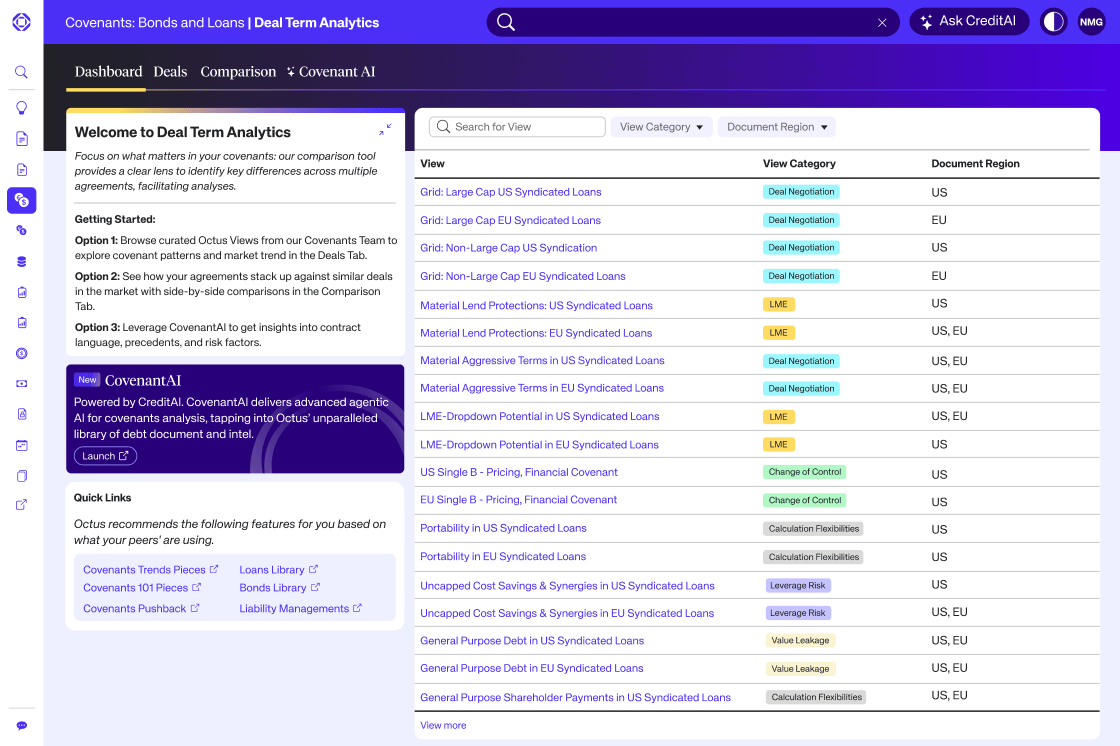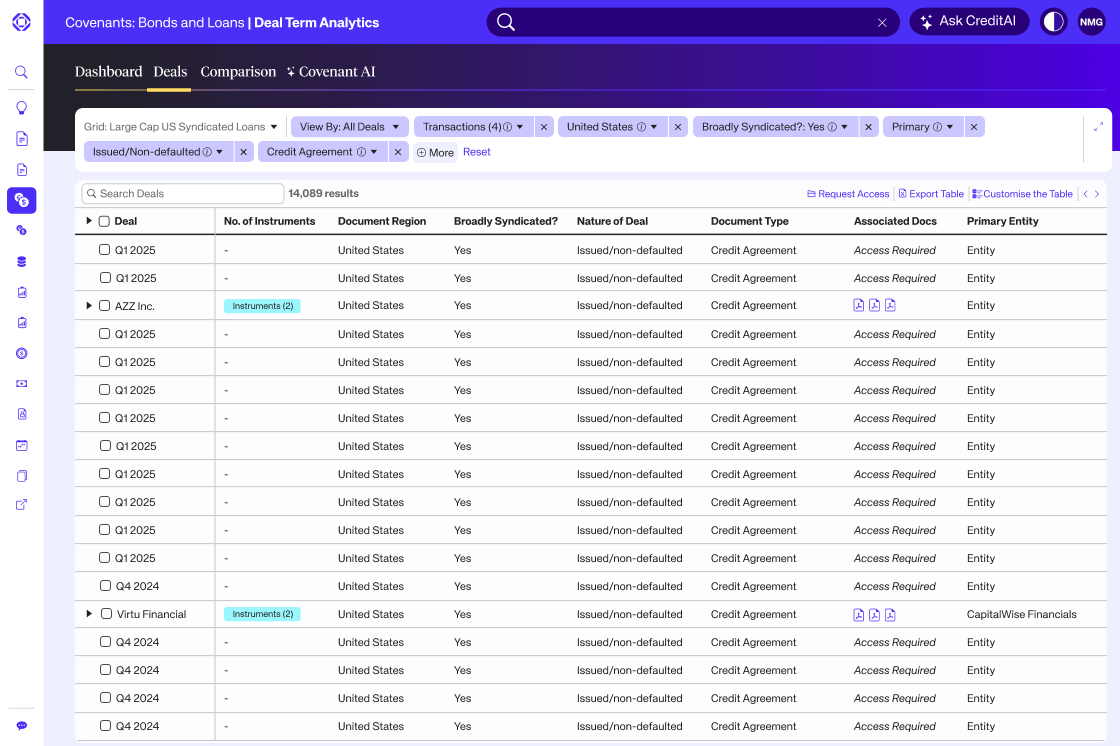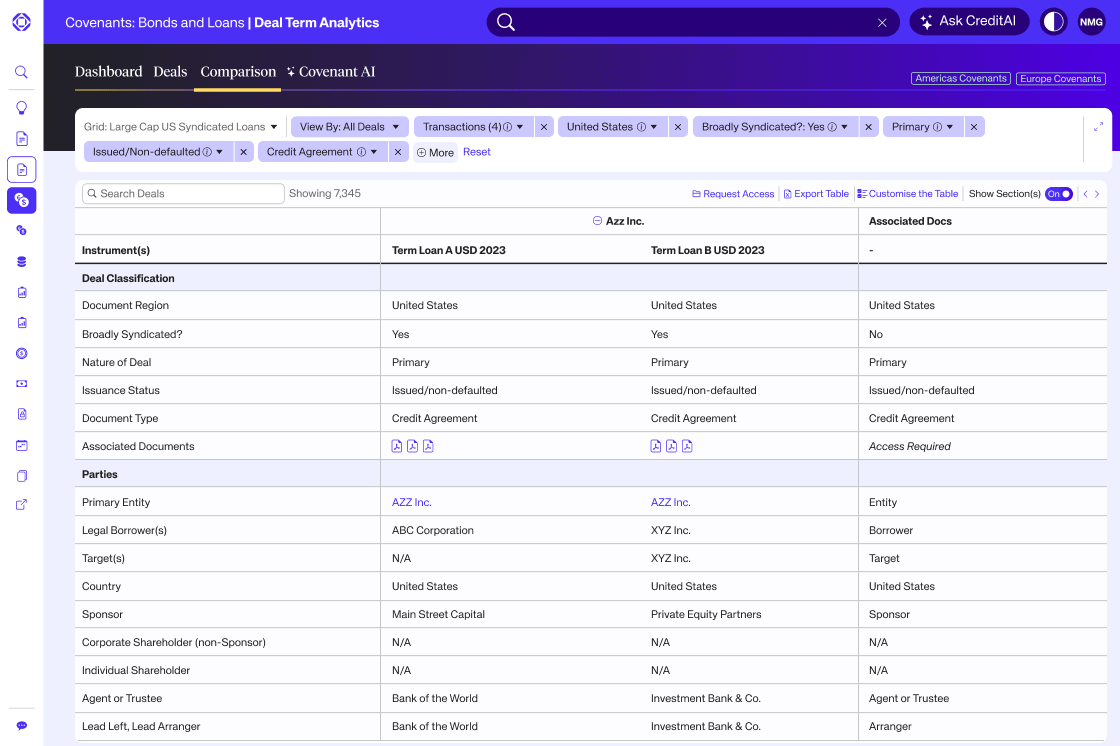
Introducing Deal Term Analytics
“Explore Deal Term Analytics"We’re utilizing generative AI agents and proprietary technologies to unlock the hidden insights within private credit data and elevate legal and investment advisors’ capabilities to better serve the clients." – Sree Mallikarjun, Chief Scientist, Head of AI Innovation, OctusChief Scientist, Head of AI Innovation Octus
Complex financials curated by humans, powered by AI
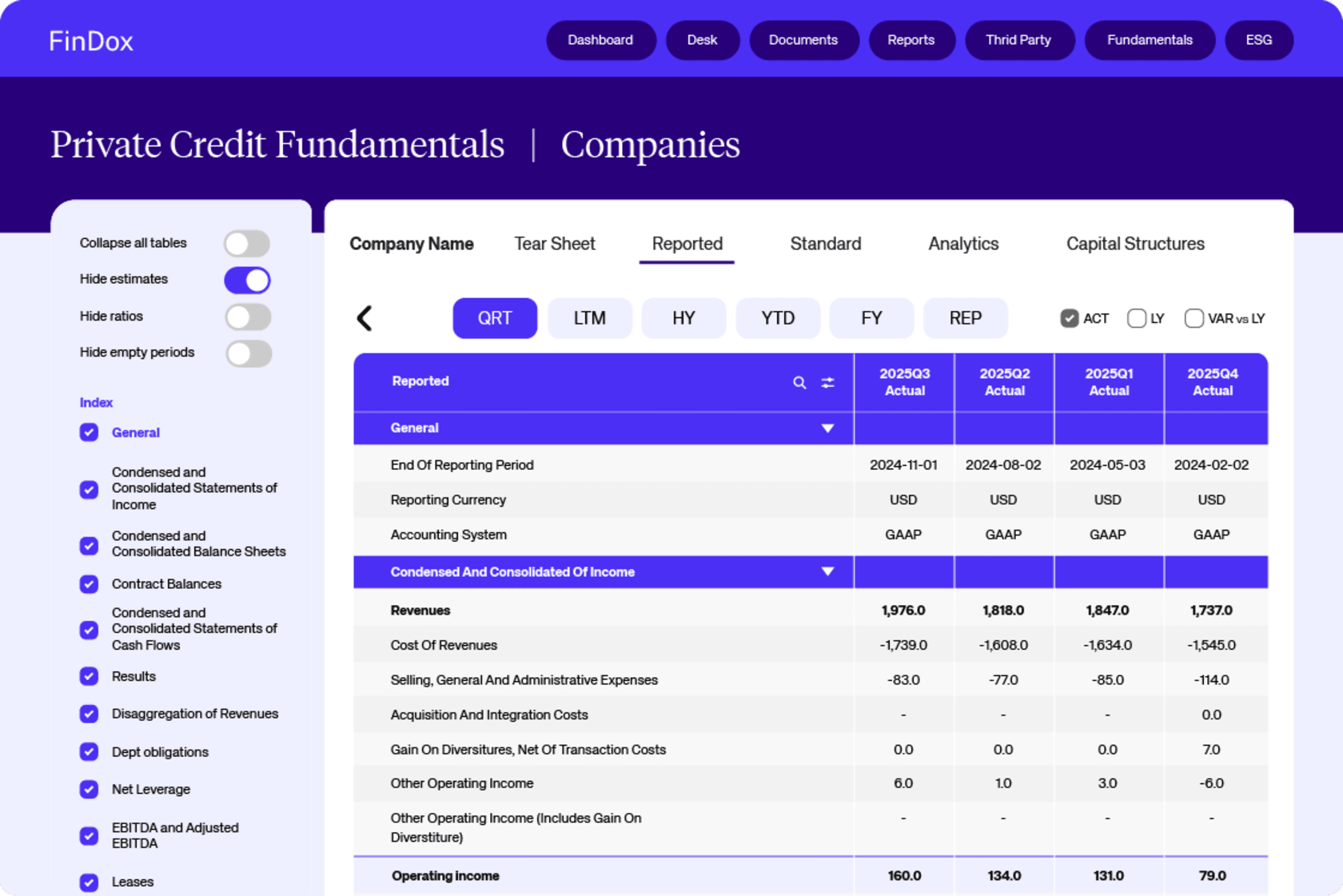
Private Credit Fundamentals
Get all the key financial info for your private credit deals, including direct lending and private equity. We’ll handle the numbers so you can focus on the important stuff: post-deal analytics and monitoring. We’ve got data for all the names you need.

FAQs
Our principles are:
- Fairness and non-discrimination: Our AI models are built to be unbiased and avoid discriminatory outcomes based on factors like race, gender, or income.
- Transparency and explainability: We strive for transparency in our AI systems. We aim to explain how decisions are made, allowing for human oversight and intervention if needed.
- Accountability: We take ownership of our AI models. We have clear roles and processes for development, deployment, and monitoring to ensure responsible use.
- Privacy and security: We prioritize user privacy and data security. We comply with all relevant regulations and implement robust security measures to protect user information.
- Human oversight: Humans remain in control. AI is a tool to augment human decision-making, not replace it.
And our practices include:
- Diverse development teams: We build diverse teams of engineers, data scientists and developers to identify and address potential biases early on.
- Fairness testing: We employ rigorous fairness testing throughout the development process to identify and mitigate bias in datasets and algorithms.
- Model explainability tools: We use explainable AI techniques, such as TruLens and Variable Importance to understand how models reach conclusions. This allows for human review and intervention if necessary.
- Human-in-the-loop systems: We design systems where humans can review and override AI decisions, particularly in critical areas.
- Regular audits and monitoring: We conduct regular audits to identify and address any emerging bias or performance issues in deployed models.
We have a well-defined ethical framework guiding AI development and deployment. This framework is based on industry best practices and regulatory guidelines. It outlines principles such as fairness, transparency, accountability, integrity and security.
The Octus AI ethical framework consists of eight pillars:
1 – Fairness: AI solutions should be designed to reduce or eliminate bias against individuals, communities and groups.
2 – Transparency: AI solutions should include responsible disclosure to provide stakeholders with a clear understanding of what is happening in each solution across the AI lifecycle.
3 – Explainability: AI solutions should be developed and delivered in a way that answers the questions of how and why a conclusion was drawn from the solution.
4 – Accountability: Human oversight and responsibility should be embedded across the AI lifecycle to manage risk and comply with applicable laws and regulations.
5 – Data integrity: Data used in AI solutions should be acquired in compliance with applicable laws and regulations and assessed for accuracy, completeness, appropriateness and quality to drive trusted decisions.
6 – Reliability: AI solutions should consistently operate in accordance with their intended purpose and scope and at the desired level of precision.
7 – Security: Robust and resilient practices should be implemented to safeguard AI solutions against bad actors, misinformation or adverse events.
8 – Safety: AI solutions should be designed and implemented to safeguard against harm to people, businesses and property.
We mitigate bias through:
- Data quality: We prioritize high-quality data with randomized and diverse representation to minimize bias in training datasets.
- Algorithmic choice: We carefully select algorithms less prone to bias and continuously evaluate new approaches for fairness.
- Human review and feedback: We incorporate human review loops and feedback mechanisms to identify and rectify biased outcomes during the development and deployment phases.
Ensuring explainability in our AI decisions is paramount. Below are the techniques with which we approach the issue:
- Feature importance: We identify the data points (features) that have the most significant influence on the model’s decision. This helps us understand which factors play a key role in its conclusions.
- Partial dependence plots: These plots visualize the impact of individual features on the model’s output. It allows us to see how a specific feature value can influence the final outcome.
- Counterfactual explanations: This technique explores “what-if” scenarios. We can see how a slight change in an input might affect the model’s prediction. This helps users understand the model’s reasoning.
- Model-Agnostic Explainable AI (XAI) methods: We utilize techniques like LIME (Local Interpretable Model-Agnostic Explanations) to create simpler, human-interpretable models that mimic the behavior of the complex AI model for specific predictions.
By leveraging the above mentioned techniques, we can provide insights into how AI models arrive at specific conclusions:
Document classification. For example, we can show which factors like headline, legal jargon, or financial jargon had the most significant impact on the specific credit related topic.
Risk index. For example, we can highlight the specific going concern language and covenants that amplify default risk for a company.
There are limitations to explainability, especially with complex models:
- Black box nature: Highly complex models can be intricate webs of connections, making it challenging to fully understand the reasoning behind every decision.
- Data-driven biases: If the underlying data has biases, the model might inherit them, making it difficult to explain biased outcomes.
- Hallucinations: In GenAI models, despite several in-house guardrails, on rare occasions, responses may contain a confusion of coreference resolution when multiple entities or persons are mentioned in a complicated narrative.
- Numerical calculations: While LLMs are effective at textual tasks, their understanding of numbers typically comes from narrative context, and they lack deep numerical reasoning or flexibility of a human mind to carry out calculations and perform human-like interpretations and complex financial or legal judgements.
- Human expertise: We rely on human expertise to interpret the explanations provided by signals observed from the source data. Subject matter expert (SME) groups from business along with our data scientists examine the results and ensure they align with ground truth.
- Documentation and transparency: We document the explainability methods used and the limitations of the model. This promotes transparency and helps users understand the level of certainty associated with the AI’s conclusions.
Our AI systems rely on a variety of data sources to train and operate effectively, which include:
- Internal data: We leverage anonymized historical product usage data. This data provides valuable insights to support our product and service offering improvements. Our data retention policy ensures data doesn’t contain any personally identifiable information (PII).
- External data: We may incorporate external datasets, anonymized and aggregated, on market trends, economic indicators and industry benchmarks. This enriches our models with a broader perspective.
We employ a comprehensive suite of security measures to protect our systems and your data. Key measures include:
- Data anonymization: We anonymize all data before using it for training or operation. This protects user privacy and ensures compliance with data privacy regulations.
- Encryption: All client data is protected with strong encryption, both at rest and in transit.
- Access Control: We enforce multi-factor authentication (MFA) for all administrative access and utilize a role-based access control scheme to ensure access is restricted to authorized personnel.
- Threat Detection: We use a threat detection monitoring tool for continuous network oversight. System firewalls are configured to limit unnecessary ports and protocols.
- Code and Data Security: We have a strict source code management protocol with access controls and automated security scans. Our databases are configured with role-based permissions and encryption.
- Employee Security: All employees and contractors undergo background checks and are required to complete annual information security and awareness training.
- Data anonymization: We anonymize all data before using it for training or operation. This protects user privacy and ensures compliance with data privacy regulations.
Rigorous testing and validation are cornerstones of our AI development process, especially for credit models that rely on credit data and news. Below are our testing processes with which we ensure the reliability and robustness of our AI systems:
- Data splitting: We split our data into training, validation and testing sets. The training set teaches the model. The validation set helps fine-tune hyperparameters to avoid overfitting; and the unseen testing set provides an unbiased assessment of the model’s generalizability.
- Performance metrics: We employ a battery of performance metrics relevant to the specific application. For credit models, this might include accuracy, precision, recall, F1 score, and Area Under the ROC Curve (AUC-ROC). These metrics tell us how well the model distinguishes between creditworthy and non-creditworthy borrowers.
- Stress testing: We stress test our models with extreme or unexpected data points to assess their resilience in unforeseen situations. This helps us identify potential weaknesses and improve the model’s ability to handle edge cases.
- Backtesting: For credit models, we can backtest the model’s performance on historical data to see how it would have performed in the past. This helps assess the model’s effectiveness and identify potential biases.
- Human-in-the-loop testing: We integrate human review into the testing process. Domain experts evaluate the model’s outputs and identify cases where the model might be making inaccurate or unfair decisions. This human oversight mitigates potential risks.
We approach this through:
- Model monitoring: We continuously monitor the performance of deployed models in production. This allows us to detect any performance degradation or shifts in the data distribution that might affect the model’s accuracy over time.
- Model retraining: Based on monitoring, we may retrain the model with new data to maintain its accuracy and effectiveness.
- Version control: We maintain a clear version control system for our models. This allows us to track changes, revert to previous versions if necessary, and ensure consistency across deployments.
We approach this through:
- Scenario testing: We develop scenarios that represent potential edge cases or unexpected situations. We test the model’s behavior in these scenarios to identify and address potential issues.
- Human oversight: We maintain human oversight capabilities within the system. Humans can intervene in critical situations or when the model’s output is deemed unreliable.
We believe in responsible AI when dealing with sensitive credit data and news. Here’s how we ensure a healthy balance between AI power and human oversight:
- Human-in-the-loop approach: We primarily follow a “human-in-the-loop” approach. Our AI models generate outputs, but our experts have the final say in credit decisions.
- Expert review: Subject matter experts (SMEs) review the AI’s outputs, considering the unique circumstances and supporting evidence. This mitigates potential bias from the model and ensures sound judgment.
We approach this through:
- Explanation and transparency: Users can track citations and underlying sources for AI-generated outputs. This allows them to understand the factors influencing the decision and identify potential areas for discussion.
- Dispute process: We have a clear dispute process in place. Users can contest AI outputs if they believe there are inaccuracies or extenuating circumstances not captured by the model. Our financial and legal experts will then review the case and make a final judgment.
We approach this through:
- Clear escalation channels: We provide clear channels for users to escalate concerns about AI outputs. This allows for swift human intervention when necessary.
- Error correction and feedback loop: We have a feedback loop in place. If human experts identify errors in the AI’s outputs, these get logged and fed back into the model training process. This helps us continuously improve the model’s accuracy and fairness.
- Algorithmic bias monitoring: We actively monitor our AI models for potential biases due to possible concept drift, covariate drift and context drift, that might creep in over time. We can then take corrective measures, such as data debiasing techniques or model retraining, to address any identified biases.
We value customer feedback and take it seriously, especially when it comes to our AI systems that utilize credit data and news. We take a customer-centric approach and provide multiple channels for customers to provide feedback or report issues related to our AI systems:
- In-app feedback forms: We integrate user-friendly feedback forms directly within our applications. This allows users to conveniently report issues or share their experience with AI-generated outputs.
- Dedicated customer support: We have a customer success team educated to address concerns about AI decisions. They can gather details, escalate issues and provide clear explanations with help of the AI team.
AI is a critical component of Octus’ security program, enhancing our ability to protect our systems with greater speed and precision. We use AI to:
- Detect misconfigurations and risky changes in our cloud environment.
- Review code continuously to surface high-impact vulnerabilities.
- Analyze access patterns to detect anomalies and automate the rightsizing of permissions.
- Identify phishing attempts and device anomalies that may be missed by human review.
- Correlate signals across systems for faster, more accurate threat alerts.
Our proactive approach to security includes:
- Implementing the NIST Secure Software Development Framework (SSDF).
- Conducting thorough security testing and code reviews during the development lifecycle.
- Implementing strong input validation to prevent common attacks like SQL injection.
- Regularly monitoring for new and emerging AI-specific threats.
- Applying the principle of least privilege to limit the potential impact of any compromise.
Octus has successfully completed a SOC 2 Type II attestation, covering the systems and processes that support FinDox™ and the Octus AI platform, a testament to our commitment to security and data protection.
Our security framework is built on six foundational pillars, each reinforced by advanced AI to enhance speed and accuracy:
- Cloud Security: We continuously monitor our cloud environments to prevent misconfigurations and secure our infrastructure.
- Application Security: Security is integrated directly into our software development lifecycle, protecting against vulnerabilities in both our code and open-source libraries.
- Identity & Access Management: We enforce centralized, strict control over employee and customer access, ensuring permissions are appropriate and immediately revoked when no longer necessary.
- Endpoint & Workforce Security: All company devices are hardened, encrypted, and equipped with remote wipe capabilities. We pair this with strong email security and mandatory workforce training to mitigate human-error risks.
- Threat Detection & Response: Our systems and networks are monitored 24/7 by our security partner, to rapidly identify and contain potential threats.
- Compliance & Governance: We maintain SOC 2 certification and conduct rigorous vendor reviews to manage supply chain risk and provide assurance to our clients and partners.
We have also adopted multiple frameworks from the National Institute of Standards and Technology (NIST) to align our security program with global best practices, including:
- NIST Cybersecurity Framework (CSF)
- NIST Secure Software Development Framework (SSDF)
- NIST AI Risk Management Framework (AI RMF) (Deployment in Q1 2026)
Protecting client data is paramount. We have implemented comprehensive data protection measures to fully comply with applicable privacy regulations like GDPR and CCPA. This includes obtaining proper consents, providing clear disclosures about data collection and use, and honoring data subject rights. Our data privacy measures are governed by strict contractual provisions and internal policies.
- Data Isolation: We isolate each client’s information through logical separation, and where appropriate, physical separation, such as maintaining client-specific vectorized databases in CreditAI use cases.
- Data Anonymization: Data is anonymized before being used for training or operational purposes.
- Strict Access Controls: We implement and enforce strict, role-based access controls to restrict access to sensitive data.
- Data Use Limitation: Data is never used or disclosed to third parties outside the scope defined in our client agreements.
- Regular Audits: We conduct regular audits of our data security practices to identify and address potential vulnerabilities.
Yes. We have a comprehensive incident response plan that is regularly tested and updated. Our plan outlines clear roles and responsibilities, communication protocols and step-by-step procedures for containing, investigating and recovering from security incidents.
Our threat detection and response capability includes 24/7 Security Operations Center (SOC) coverage through a third party. We have also implemented automation to respond immediately to security alerts—such as disabling a compromised account or isolating a device—reducing our response time from hours to minutes.
Contact Us
Want to elevate your decision-making in the credit market landscape? Reach out today to learn about Octus solutions to meet your needs.